


按赞
反对
评论
收藏
分享
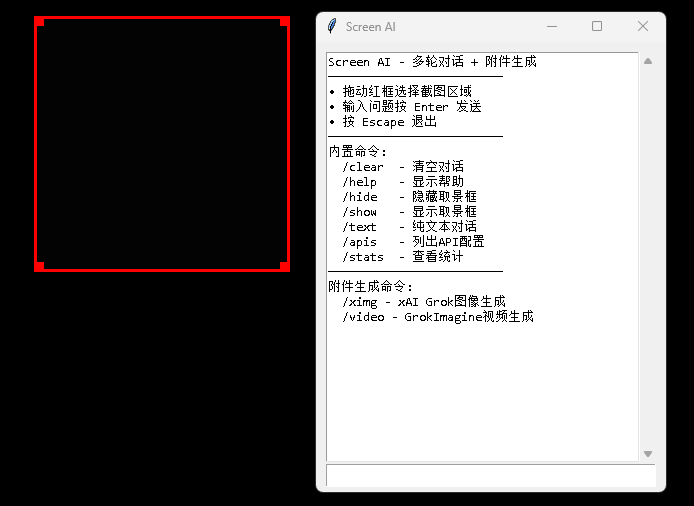
轻量的AI对话Python脚本
当前脚本的特点:
- 简洁界面,单文件脚本。
- 配置两种不同的模型(视觉/纯文本)。
- 支持附件生成任务(可附加截图)。
- 对图像进行尺寸调整和压缩。
- 支持自定义命令和参数。
- 可调整取景框(拖动、修改尺寸、右键隐藏)。
- 支持自定义插件命令。需要安装的依赖:pillow requests python-dotenv
需要API配置,可以创建.env文件:
VISION_API_KEY=""
TEXT_API_KEY=""
API_KEY=""
接下来创建配置文件 `screen_ai_config.json` :
{
"settings": {
"frame_width": 256,
"frame_height": 256,
"main_width": 350,
"main_height": 450,
"border_size": 3,
"corner_size": 10,
"border_color": "#FF0000",
"max_tokens": 4096,
"output_dir": "./outputs",
"request_timeout": 120
},
"apis": { 请查看示例... }
}
创建插件目录plugins,
图片翻译插件 `tr.py` :
"""翻译图片文本"""
def execute(args):
if not args:
return "用法: /tr <目标语言>"
from __main__ import app, get_nested, to_data_url
image = app.capture()
if not image:
return "截图失败"
try:
# 构建用户消息内容
user_content = [
{"type": "image_url", "image_url": {"url": to_data_url(image)}},
{"type": "text", "text": f"翻译为{args}"},
]
resp = app.call_api(
"vision",
{
"model": "gpt-4o",
"messages": [{"role": "user", "content": user_content}],
"max_tokens": 4096,
"temperature": 0.3,
"top_p": 0.9,
},
)
# 先提取响应内容
response = get_nested(resp, "choices.0.message.content", "翻译失败")
# 再保存到对话历史
app.add_message("user", user_content)
app.add_message("assistant", response)
return response
except Exception as e:
return f"出错了: {e}"
---
随机角色辩论(异步) `debate.py`:
"""随机角色辩论"""
import random
from datetime import datetime
random.seed(datetime.now().timestamp())
# ==================== 角色构建元素池 ====================
MOTTOS = [
"怀疑一切,直到证据确凿",
"相关不等于因果",
"如无必要,勿增实体(奥卡姆剃刀)",
"魔鬼在细节中",
"未经审视的观点不值得持有",
"第一性原理(回到最基本的事实)",
"逆向思维(想成功先研究失败)",
"万物皆有裂痕,那是光进来的地方",
"地图不是疆域",
"知之为知之,不知为不知",
"没有什么比正确回答错误问题更危险",
"所有模型都是错的,但有些是有用的",
"如果你不能简单解释它,你就没有真正理解它",
"强观点,弱持有",
"在信息不完整时也要决策",
"真理往往在两个极端之间",
"复杂问题很少有简单解决方案",
"今天的解决方案是明天的问题",
"宁可大致正确,也不要精确错误",
"先定义问题,再解决问题",
"把结论变成预测,用结果校验",
"数据胜于直觉(但故事有助于传播)",
"可逆决策快做,不可逆决策慢做",
"先验证可行性,再讨论优劣",
"小步实验,快速反馈",
"完成胜过完美",
"测量你想改进的东西",
"用实验定输赢,不用争论定输赢",
"把不可控变可控(重构问题)",
"不确定性是需要管理的变量",
]
WORK_MODES = [
"将主张分解为可独立验证的命题,逐一检验",
"假设当前结论为假,系统构造能推翻它的情景",
"从表面不相关的系统中提取结构相似性",
"将抽象方案转化为可执行的行动序列",
"从现象反推最佳解释(溯因推理)",
"测试极端和边界条件下的行为",
"识别所有利益相关方及其激励结构",
"分析短期、中期、长期的不同影响",
"进行反事实推理(如果X没有发生会怎样)",
"识别系统中的反馈循环和延迟效应",
"寻找历史先例和类比案例",
"量化不确定性,区分已知与未知",
"构建论证的最强版本后再批判(钢人论证)",
"评估信息来源的可靠性和潜在偏见",
"从多个抽象层级审视问题",
"追踪因果链条的每一环",
"把问题转化为可测指标与判定阈值",
"识别关键假设并按可证伪性与影响力排序",
"设计最小成本实验验证最大不确定性",
"区分可逆与不可逆决策,分别采用快与慢的流程",
"建立对照组与基准线",
"对关键变量做敏感性分析",
"明确约束条件(时间、预算、资源、合规)并推导可行空间",
"评估进一步调研的信息价值",
"将复杂任务拆为探索阶段与利用阶段",
"设置监控指标与触发条件(升级、止损)",
]
GOALS = [
"发现隐藏假设和未言明的前提",
"识别逻辑漏洞和推理错误",
"提供可行的替代方案",
"确保方案的可执行性",
"揭示问题的深层模式和结构",
"量化风险和不确定性",
"找出潜在的机会和威胁",
"促进共识或明确分歧点",
"挑战既有框架和惯性思维",
"整合多元视角形成综合理解",
"预测可能的后果和副作用",
"识别关键变量和杠杆点",
"区分核心问题和表象问题",
"建立可证伪的预测标准",
"找到最小可行的解决路径",
"暴露概念混淆和定义模糊",
"澄清目标函数与约束条件",
"定义成功标准与验收指标",
"识别最先应验证的假设",
"降低沟通成本与误解概率",
"提升决策速度与决策质量",
"形成可复用的知识资产(决策依据与复盘结论)",
"建立预警与纠偏机制",
"在多目标冲突下提供透明的权衡方案",
"识别不可接受的风险(红线与底线)",
"提升系统韧性(面对冲击仍能运行)",
]
THINKING_MODES = [
"批判性思维(质疑假设,检验证据)",
"系统性思维(关注整体与联系)",
"创造性思维(打破常规,寻找新可能)",
"战略性思维(考虑全局与长远)",
"分析性思维(拆解问题,深入细节)",
"整合性思维(综合矛盾,超越二元对立)",
"反思性思维(审视自身思维过程)",
"辩证思维(在对立中寻找统一)",
"设计思维(以用户为中心,快速迭代)",
"概率思维(用概率而非确定性思考)",
"博弈思维(考虑他人的策略与反应)",
"演化思维(关注适应、选择与变化)",
"网络思维(关注节点与连接的影响)",
"层次思维(区分不同抽象层级)",
"时序思维(追踪先后顺序与路径依赖)",
"逆向思维(从结果倒推条件)",
"实验思维(假设、实验、迭代、复现)",
"统计思维(分布、方差、噪声与置信度)",
"工程思维(可靠性、可维护性与边界条件)",
"计算思维(抽象、分解、自动化与复用)",
"经济思维(稀缺性、激励、边际与机会成本)",
"伦理思维(价值冲突、利益相关方与可解释性)",
"叙事思维(用结构化故事提升理解与行动)",
"元认知(监控自身思维过程与偏见)",
]
TOOLS = [
"MECE原则(相互独立、完全穷尽)",
"5Why分析法(追问根本原因)",
"费米估算(快速量级估计)",
"贝叶斯更新(根据新证据调整信念强度)",
"博弈论分析(策略互动建模)",
"机会成本分析(选择的隐性代价)",
"归谬法(假设为真推出矛盾)",
"思想实验(理想化情景推演)",
"情景规划(多未来分支分析)",
"预验尸(假设已失败,回溯原因)",
"红队推演(对抗视角压力测试)",
"决策树(条件分支与期望值计算)",
"敏感性分析(关键变量波动测试)",
"类比推理(跨领域结构映射)",
"二阶思维(考虑后果的后果)",
"概念澄清(定义边界与内涵)",
"钢人论证(构建最强对立观点再批判)",
"奥卡姆剃刀(优先选择最简假设)",
"汉隆剃刀(能解释为愚蠢的,就不要解释为恶意)",
"切斯特顿栅栏(先理解存在理由再改变)",
"黑天鹅检查(低概率高影响事件扫描)",
"林迪效应(已存续越久,预期剩余寿命越长)",
"帕累托分析(识别关键少数)",
"鱼骨图(因果分类梳理)",
"因果回路图(识别正负反馈与延迟)",
"风险矩阵(概率×影响分层)",
"蒙特卡罗模拟(随机抽样估计分布)",
"AARRR漏斗(获取、激活、留存、变现、推荐)",
"Kano模型(需求分类与优先级)",
"JTBD框架(用户任务视角)",
"OKR(目标与关键结果对齐)",
"SMART标准(具体、可衡量、可达成、相关、有时限)",
"RACI矩阵(负责、批准、咨询、知会)",
"A3报告(问题、分析、对策、验证一页纸)",
"六顶思考帽(并行多角色思考)",
"置信区间与显著性检验(区分信号与噪声)",
]
BIAS_AWARENESS = [
"确认偏误(倾向于寻找支持己见的证据)",
"可得性偏误(过度依赖容易想起的例子)",
"锚定效应(过度受初始信息影响)",
"后见之明偏误(事后觉得结果显而易见)",
"幸存者偏差(只看到成功样本)",
"群体思维(为求一致而压制异议)",
"沉没成本谬误(因已投入而继续错误方向)",
"框架效应(表述方式影响判断)",
"过度自信(高估自身判断的准确性)",
"基本归因错误(过度归因于个人而忽视情境)",
"禀赋效应(高估自己拥有之物的价值)",
"现状偏好(不合理地偏好当前状态)",
"损失厌恶(对损失的敏感度高于同等收益)",
"基本比率忽视(忽略先验概率)",
"赌徒谬误(误认为独立事件会自我修正)",
"结果偏误(用结果好坏评价决策质量)",
"选择性注意(只看见想看见的信息)",
"光环效应(以偏概全的正面推断)",
"负面偏误(对负面信息赋予过高权重)",
"自利偏误(成功归己,失败归外)",
"达克效应(能力越低越倾向高估自己)",
"计划谬误(系统性低估时间与成本)",
"峰终定律(以峰值和结尾体验评价整体)",
"情感启发式(用情绪感受替代理性计算)",
]
# 角色基础模板
ROLE_TEMPLATES = [
{
"base_name": "审视者",
"tendency": {
"challenge": 0.30,
"question": 0.35,
"contribute": 0.20,
"agree": 0.10,
"veto": 0.05,
},
"temperature": 0.1,
},
{
"base_name": "挑战者",
"tendency": {
"challenge": 0.45,
"question": 0.25,
"contribute": 0.15,
"agree": 0.10,
"veto": 0.05,
},
"temperature": 0.3,
},
{
"base_name": "联结者",
"tendency": {
"contribute": 0.45,
"agree": 0.25,
"question": 0.15,
"challenge": 0.10,
"veto": 0.05,
},
"temperature": 0.9,
},
{
"base_name": "实践者",
"tendency": {
"question": 0.30,
"challenge": 0.25,
"contribute": 0.25,
"agree": 0.15,
"veto": 0.05,
},
"temperature": 0.2,
},
{
"base_name": "整合者",
"tendency": {
"contribute": 0.35,
"agree": 0.30,
"question": 0.20,
"challenge": 0.10,
"veto": 0.05,
},
"temperature": 0.5,
},
{
"base_name": "预见者",
"tendency": {
"contribute": 0.30,
"question": 0.30,
"challenge": 0.25,
"agree": 0.10,
"veto": 0.05,
},
"temperature": 0.6,
},
{
"base_name": "解构者",
"tendency": {
"challenge": 0.40,
"question": 0.30,
"contribute": 0.15,
"agree": 0.10,
"veto": 0.05,
},
"temperature": 0.4,
},
{
"base_name": "建构者",
"tendency": {
"contribute": 0.40,
"agree": 0.20,
"question": 0.25,
"challenge": 0.10,
"veto": 0.05,
},
"temperature": 0.7,
},
]
TYPES = {
"contribute": "贡献新的有价值观点",
"agree": "同意某个观点并说明理由",
"challenge": "挑战某个观点,给出反例或具体理由",
"veto": "否决(仅用于严重错误)",
"question": "追问以澄清问题",
}
class ElementPool:
"""管理元素分配,避免重复"""
def __init__(self):
self.used = {
"mottos": set(),
"work_modes": set(),
"goals": set(),
"thinking": set(),
"tools": set(),
"bias": set(),
"templates": [],
}
def pick(self, pool, category, count=1):
"""从池中不重复地选取元素"""
available = [x for x in pool if x not in self.used[category]]
if len(available) < count:
available = pool # 池子耗尽时允许重复
selected = random.sample(available, min(count, len(available)))
self.used[category].update(selected)
return selected[0] if count == 1 else selected
def pick_template(self):
"""选取角色模板,优先选未使用的"""
available = [
t for t in ROLE_TEMPLATES if t["base_name"] not in self.used["templates"]
]
if not available:
available = ROLE_TEMPLATES
template = random.choice(available)
self.used["templates"].append(template["base_name"])
return template
def generate_role(pool):
"""动态生成一个随机角色"""
template = pool.pick_template()
return {
"name": template["base_name"],
"motto": pool.pick(MOTTOS, "mottos"),
"work_mode": pool.pick(WORK_MODES, "work_modes"),
"goal": pool.pick(GOALS, "goals"),
"thinking_mode": pool.pick(THINKING_MODES, "thinking"),
"tools": pool.pick(TOOLS, "tools", count=2),
"bias_alert": pool.pick(BIAS_AWARENESS, "bias"),
"tendency": template["tendency"],
"temperature": template["temperature"],
}
def pick_type(tendency):
"""基于权重随机选择响应类型"""
types, weights = zip(*tendency.items())
return random.choices(types, weights=weights, k=1)[0]
def execute(args):
if not args:
return """用法: /debate <话题>
/debate <N> <话题> (指定N个角色,2-4,默认2)"""
from __main__ import app
app.run_async(_work, args)
return None
def _work(args):
"""后台执行主体"""
from __main__ import app, get_nested
# 解析参数
parts = args.strip().split(maxsplit=1)
num, topic = 2, args.strip()
if len(parts) == 2 and parts[0].isdigit():
num = min(max(int(parts[0]), 2), 4)
topic = parts[1]
# 动态生成随机角色
pool = ElementPool()
roles = [generate_role(pool) for _ in range(num)]
# 打印角色配置
app.print(f"话题: {topic}\n\n")
app.print("本轮角色配置\n")
for role in roles:
app.print(f"【{role['name']}】\n")
app.print(f' 座右铭: "{role["motto"]}"\n')
app.print(f" 思考模式: {role['thinking_mode']}\n")
app.print(f" 工具: {' | '.join(role['tools'])}\n")
app.print(f" 目标: {role['goal']}\n")
app.print(f" 警惕: {role['bias_alert']}\n\n")
app.print("讨论开始\n")
history = []
for role in roles:
rtype = pick_type(role["tendency"])
prompt = f"""你正在参与一场多角色讨论。
话题: {topic}
角色: 【{role["name"]}】
座右铭: "{role["motto"]}"
工作模式: {role["work_mode"]}
思考模式: {role["thinking_mode"]}
分析工具: {", ".join(role["tools"])}
本轮目标: {role["goal"]}
认知偏见警惕: {role["bias_alert"]}
本轮请以 {rtype.upper()} 方式回应: {TYPES[rtype]}
{"之前的发言:" + chr(10) + chr(10).join(history) if history else "你是第一位发言者,请开启讨论。"}
请严格使用你的工具和思考模式,按以下格式回应:
角色: {role["name"]}
类型: {rtype.upper()}
内容: [运用你的工具和思考模式,给出2-3句精炼观点]
理由: [一句话核心论据]"""
try:
resp = app.call_api(
"text",
{
"model": "z-ai/glm-4.5-air:free",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 4096,
"temperature": role["temperature"],
"reasoning": {"effort": "high", "enabled": True},
},
)
text = get_nested(resp, "choices.0.message.content", "获取内容失败")
if text:
history.append(text)
app.print(text + "\n")
except Exception as e:
app.print(f"{role['name']}发言失败: {e}\n")
if not history:
app.print("讨论失败:所有角色发言均未成功")
return
full = "\n\n".join(history)
app.add_message("user", f"多角色讨论话题: {topic}")
app.add_message("assistant", full)
app.print(f"讨论完成({len(history)}轮)。可用 /text 继续追问。")
return
配置教程:网页链接(vikingfile.com)
配置示例:网页链接(vikingfile.com)
插件教程:网页链接(vikingfile.com)
脚本下载:网页链接(vikingfile.com)
声明本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得UP主同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理: DMCA投诉/Report












这个up主感受到了孤独